Ben Pitler
Human rights defender and University of Washington MBA candidate, data science/analytics track. Passionate about using data science to achieve justice.
This portfolio details my use of data science to investigate and document violations of international human rights law. Please direct all questions and requests to collaborate to ds4hrbp@protonmail.com
LinkedIn
Scraping the web for execution announcements in Saudi Arabia
Saudi Arabia executes dozens of people each year; the Kingdom is usually among the top three executing states in the world. Many of these executions are carried out for non-violent offences, and the trials leading to executions in Saudi Arabia consistently fail to meet international minimum standards for fair trial protections. The rapid pace of executions in Saudi Arabia makes it difficult for human rights defenders to keep track of who is killed by the Kingdom’s government. Moreover, the Saudi government does not disseminate any kind of codified database detailing who is executed and when. News of executions is instead published by the state-run Saudi Press Agency (SPA).
Each time the Kingdom carries out an execution, the SPA publishes an article announcing the execution; these articles are buried among hundreds more mundane pieces on the SPA website. This means that the only way for human rights organizations and activists to reliably track and document all executions in Saudi Arabia is to sift through huge numbers of links on the SPA website, searching for information about executions. I wanted to automate this process, using rvest to crawl through the SPA website and return URLs only for execution announcements.
Determining search terms
There is no “executions” tag on the SPA website, so we need to use a search term that will return all execution announcements. The search term I chose is the Arabic word “حكم”, which means “judgement” or “verdict”. All SPA execution announcement headlines include the phrase “تنفيذ حكم”, which means “implementation of verdict”, so a search for “حكم” should return all execution announcements:
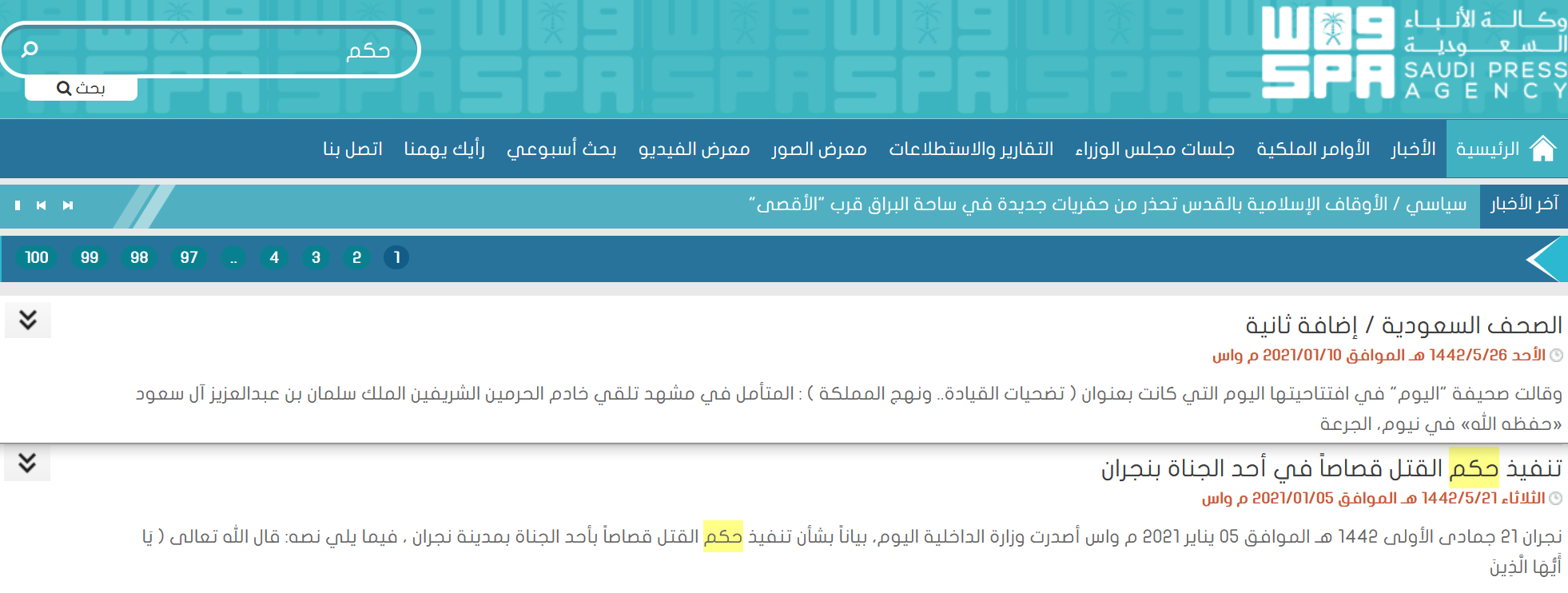
Determining filtering terms
From there, we need to find a way to filter the larger set of search results whose headlines contain the word “حكم” into a smaller subset that contains exclusively execution announcements. I chose the word “تنفيذ” itself, as that seems to be present only in execution announcement headlines.
Examining the HTML
Now we need to inspect the SPA website’s HTML to determine exactly where the headline text sits within the search results page. The SPA search results (e.g.) are dynamically retrieved by Ajax (e.g.), so that’s where we need to look.
When we inspect the HTML on that Ajax retrieval page, we find that the actual hyperlink/headline titles are contained in the “h2NewsTitle” node, and the corresponding URLs are contained in the “aNewsTitle” node:

Creating the scraping script
With that information, we can use rvest to create a script that will return a list of all URLs for execution announcements on a given search results page:
library(tidyverse)
library(rvest)
//]: # Crawls through HTML on the first page of results for the search term "حكم" and returns all matching titles:
list1 <- read_html("https://www.spa.gov.sa/ajax/search.php?searchbody=1&search=%D8%AD%D9%83%D9%85&cat=0&cabinet=0&royal=0&lang=ar&pg=1&pg=1") %>% html_nodes(".h2NewsTitle") %>% html_text()
[//]: # Crawls through same HTML and returns corresponding URLs:
list2 <- read_html("https://www.spa.gov.sa/ajax/search.php?searchbody=1&search=%D8%AD%D9%83%D9%85&cat=0&cabinet=0&royal=0&lang=ar&pg=1&pg=1") %>% html_nodes(".aNewsTitle") %>% html_attr("href")
[//]: # Returns indices of all list1 elements containing the word "تنفيذ", which appears only in execution announcements:
grep_list <- grep("تنفيذ", list1)
[//]: # Creates blank list:
link_list <- vector("list", length(grep_list))
[//]: # Populates blank list with URLs corresponding to titles of execution announcements in grep_list:
for (i in grep_list){
link_list[i] <- paste("https://www.spa.gov.sa", list2[i], sep = "")}
[//]: # Removes null values:
link_list = link_list[-which(sapply(link_list, is.null))]
[//]: # Creates data frame and exports to .csv file:
link_df <- as.data.frame(link_list)
link_df <- t(link_df)
write.csv(link_df,"C:/Users/benpi/OneDrive/Documents/R/ksa_executions.csv", row.names = FALSE)
This creates a .csv file that contains a list of the relevant URLs:
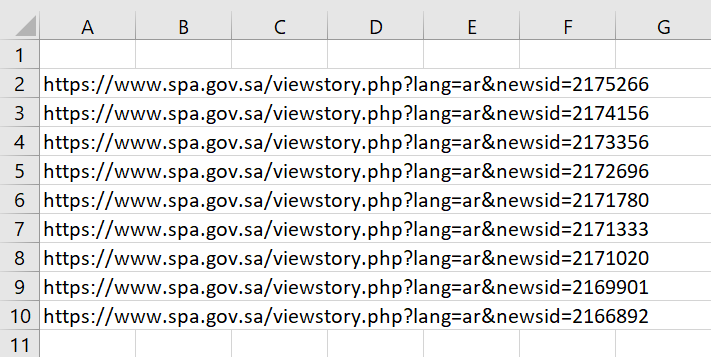
The script only crawls through one page at a time. This could be sufficient, if one runs the script once a week, but I may also edit it in the future so that it runs through all available search results pages and appends only new URLs that it hasn’t found previously.