Ben Pitler
Human rights defender and University of Washington MBA candidate, data science/analytics track. Passionate about using data science to achieve justice.
This portfolio details my use of data science to investigate and document violations of international human rights law. Please direct all questions and requests to collaborate to ds4hrbp@protonmail.com
LinkedIn
Using RSelenium to scrape the web for court cases in Indonesia
This is a project I’m working on for a journalist friend who investigates environmental justice issues in Southeast Asia. One such issue relates to prosecutions of smallholder farmers in Indonesia. Indonesia has a major problem with air pollution, and in particular smoky haze, which blankets parts of Southeast Asia each year. Much of this haze originates in Indonesia, on the islands of Sumatra and Borneo, and then wafts across the water to Malaysia and Singapore; the haze is a source of diplomatic tension in the region, as well as a major health hazard.
The source of this haze, in part, is deliberate burning to clear land area in Sumatra and Borneo. It is true that small farmers in these places have practiced swidden agriculture for generations, but the large palm oil and pulpwood conglomerates based in Indonesia also use these tactics on a much larger scale to make space for expanding their plantations. Nevertheless, the Indonesian judiciary continues to prosecute small farmers for burning land, while relatively few plantation concerns are punished.
Information regarding the prosecution of farmers for burning is posted on a series of websites hosted by Indonesia’s judiciary; each website pertains to a different federal district of Indonesia, and lists prosecutions and court cases for that district:
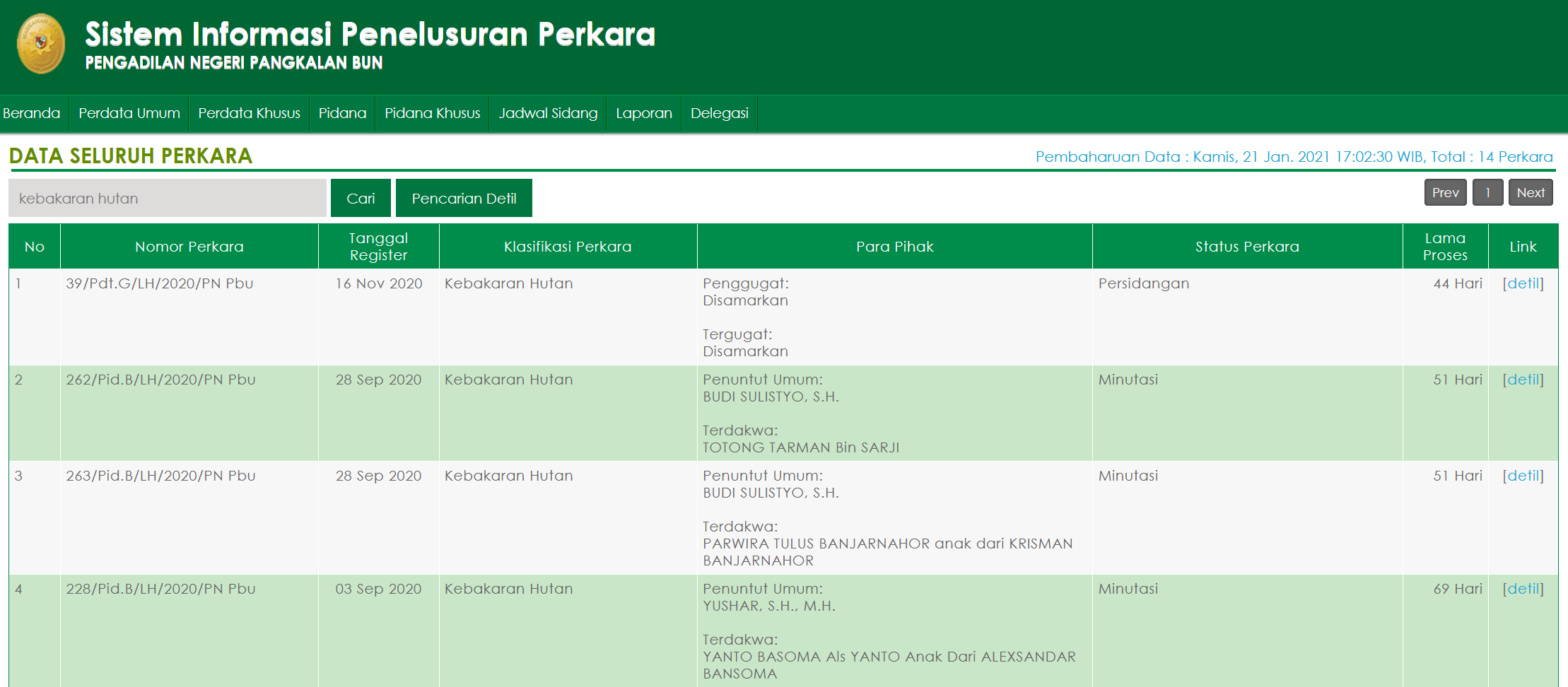
Compared to the data disclosure practices of governments in other parts of the world where I have worked (especially the Middle East), the Indonesian government’s approach isn’t terrible. When you navigate to a court website, you can search for a term and return an organized table that summarizes all of the search results and provides links for more detail. That said, there are still quite a few barriers here to easily extracting and processing real time data about court cases. For one thing, these results tables are not downloadable in any kind of PDF or Excel file format; they’re just static HTML pages. Additionally, there’s no filtering functionality, so the only way to access results is through keyword search. As a result journalists and rights activists documenting prosecutions of small farmers spend a lot of time on these websites, entering search terms, scrolling through results, and manualy entering data. I wanted to automate this process so they always have an up-to-date database showing the current state of these court cases.
Scraping packages
Prior to starting this project, I had only done webscraping of static websites using rvest. This project is a bit more complex, because the search results on these court websites are dynamically retrieved with javascript. This means that when you perform a search, the page URL itself does not change, so you can’t enter a search results-specific URL and just scrape that page. Instead, I used the RSelenium package, which essentially allows you to run a dummy browser within an R session. This has applications not only in web scraping, but also in software testing. For web scraping purposes, you can actually use R code to direct your R session to open a browser, enter a search term, click the search button, and download the HTML from the dynamically-retrieved results page, even though the URL never changes. Then you can use rvest to actually scrape the contents of the HTML. Pretty cool!
Docker
Though this can be done directly inside of an R environment, best practice for using selenium is to use a Docker container. Docker is platform that allows you to set up a virtual environment within which to run a software applications. Doing this for selenium involves downloading Docker and then using the Windows command prompt to launch a selenium image within Docker. I found instructions [here] (https://cran.r-project.org/web/packages/RSelenium/vignettes/docker.html).
Search strategy
Before I began coding, I needed to identify the search terms I want to use to identify cases related to the prosecution of farmers. I include two such search terms here: “Kebakaran Hutan”, which means “Forest Burning”, and “Hal-hal yang mengakibatkan kerusakan dan pencemaran lingkungan”, which means “Causing damage and enviromental pollution”. These two case classifications are the search terms I used to narrow search results to land burning cases. In the screenshot at the top of this post, you see a table with a number of columns, one of which is titled “Klasifikasi Perkara”, which means “Case Classification.” This is where these search terms will appear.
Once I had these search terms, my task was to write a script that navigated to a court website and scraped the results for these search terms. One thing to note is that, as stated above, each district court has its own separate website, and there are hundreds of such districts in Indonesia. Land burning cases are mostly concentrated in Sumatra and Borneo, but you still need to examine 27 websites to find all relevant results. So the script in this post is an example that crawls one court website (for the Pangkalan Bun district) for results for the “Kebakaran Hutan” search term. I’m still working on how exactly to make this script to scrape all 27 websites for both search terms sequentially. For now though, this script allows for the easy extraction of relevant case information from any court website through the manipulations of small bits of text within the R code.
Code
The first step after launching my Docker container via the command prompt was to initiate a firefox browser via selenium and navigate to the website I wanted to search:
remote_driver <- RSelenium::remoteDriver(
remoteServerAddr = "localhost",
port = 4445L,
browserName = "firefox")
remote_driver$open()
remote_driver$navigate("http://sipp.pn-pangkalanbun.go.id/list_perkara/search")
Next, I had to locate the search field on the website, enter the search term, and direct R to click on the ‘search’ button:
[//]: #Locate search box
search_element <- remote_driver$findElement(using = 'id', value = 'search-box')
[//]: #Enter search term
search_element$sendKeysToElement(list("Kebakaran Hutan"))
[//]: #Locate search button
button_element <- remote_driver$findElement(using = 'id', value = 'search-btn1')
[//]: #Click search button
button_element$clickElement()
This brings up the table that I want to scrape, which looks like the screenshot at the top of this post. However, while I did a search for “Kebakaran Hutan”, which should in theory restrict the results to only those cases which had a value of “Kebakaran Hutan” in the “Klasifikasi Perkara” field, in practice cases may appear that have some reference to “Kebakaran Hutan” elsewhere in their text. Accordingly, I needed to next sort this table to bring those cases to the top which truly had a value of “Kebakaran Hutan” in the “Klasifikasi Perkara” field by directing R to click on the “Klasifikasi Perkara” heading at the top of the table:
[//]: #Locate "klasifikasi perkara" field, so we can sort by it
button_element2 <- remote_driver$findElement(using = 'xpath', value = "//table[@id='tablePerkaraAll']/tbody/tr/td[4]")
[//]: #Click klasifikasi perkara button
button_element2$clickElement()
Now I was ready to scrape the results of the table itself, clean up the data, and export it as a clean .csv file that contains all of the relevant information about the search results, including hyperlinks to learn more information about each case:
[//]: #Extract results table as html_table
scraped_table <- read_html(remote_driver$getPageSource()[[1]]) %>%
html_nodes(xpath = '//*[@id="tablePerkaraAll"]') %>% html_table()
[//]: #Convert table to data frame
scraped_table_df <- as.data.frame(scraped_table)
[//]: #Rename table columns, adding underscores
colnames(scraped_table_df) <- c("No", "Nomor_Perkara", "Tanggal_Register", "Klasifikasi_Perkara", "Para_Pihak",
"Status_Perkara", "Lama_Proses", "Link")
[//]: #Remove first row (which has column names in it)
scraped_table_df = scraped_table_df[-1,]
[//]: #Remove rownames
rownames(scraped_table_df) = NULL
[//]: #Delete "Link" column, which currently has just the hyperlink title in it ("detil")
scraped_table_df <- scraped_table_df[, -8]
[//]: #Convert "No" column to integer
scraped_table_df$No <- as.integer(scraped_table_df$No)
[//]: #Retrieve all URLs on the page residing in the "a" node. This returns all of the URLs on the whole page, which is too many. The last "n" of these links are the ones we want, where "n" is the number of rows in scraped_table_df
links <- read_html(remote_driver$getPageSource()[[1]]) %>%
html_nodes("a") %>% html_attr("href")
[//]: #Turn "links" into a list
link_list <- as.list(links)
[//]: #Retain only the last "n" links, where "n" is the number of rows in scraped_table_df
link_list_2 <- tail(link_list, (nrow(scraped_table_df)))
[//]: #Append link_list_2 to scraped_table_df as "Link" column:
scraped_table_df$Link <- sapply(link_list_2, paste0)
[//]: #Write the dataframe to a .csv file
write.csv(scraped_table_df, "farmers_r_sheet.csv", row.names = FALSE)